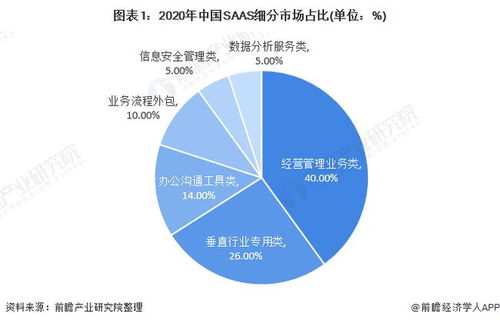
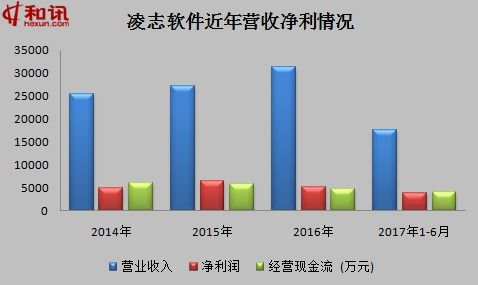
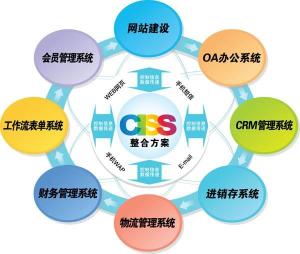
如若轉載,請注明出處:http://www.haogf.cn/product/63.html
更新時間:2026-06-19 16:08:25
地址:浙江省寧波市象山縣爵溪街道龍溪公寓3號樓3單元402室(住宅、自主申報)
電話:-
Copyright © 2026 www.haogf.cn 軟件外包 象山至尚網絡科技工作室 軟件外包 版權所有 Sitemap